Druid 高性能实时分析数据存储系统概览

Druid 是一个开源的、分布式的、列式存储的实时分析数据系统,专为处理大规模数据集的低延迟查询而设计。它广泛应用于在线分析处理(OLAP)、业务智能和实时监控场景。
主要特点
- 实时数据摄入:支持从流式数据源(如Kafka、Kinesis)和批处理数据源(如HDFS)实时摄入数据。
- 低延迟查询:提供亚秒级的查询响应时间,适用于交互式分析。
- 高可用性和可扩展性:通过分布式架构支持水平扩展,自动处理节点故障。
- 列式存储:优化了聚合查询和扫描操作,减少I/O开销。
- 时间序列优化:内置对时间序列数据的支持,便于按时间范围查询和聚合。
- 灵活性:支持多种数据格式和查询语言(如SQL和原生JSON查询)。
- 多租户支持:可隔离不同用户或应用的数据和查询负载。
设计原则
Druid 的设计遵循以下核心原则:
- 快速查询:通过预聚合、索引和列式存储来最小化查询延迟。
- 可扩展性:采用无共享架构,允许动态添加节点以处理增长的数据量和查询负载。
- 容错性:系统自动复制数据和重新分配任务,确保在节点故障时持续运行。
- 简单性:提供直观的数据模型和API,简化开发和维护。
- 云原生:支持在容器化环境(如Kubernetes)中部署,适应现代基础设施。
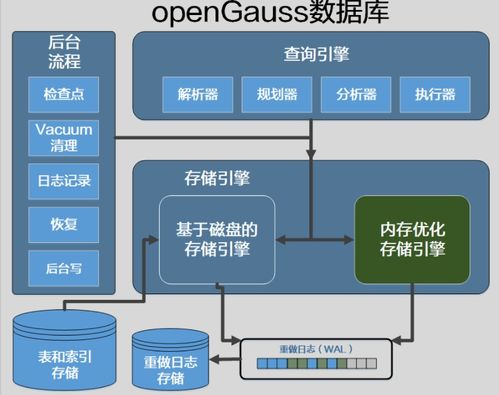
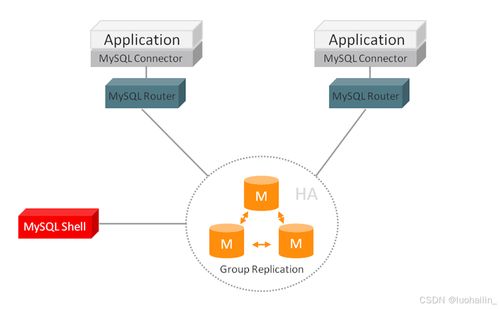
架构
Druid 的架构由多个协调组件组成,包括:
- Master 节点:负责数据管理和任务协调,包括Coordinator(管理数据段)和Overlord(控制数据摄入)。
- Data 节点:处理数据存储和查询,包括Historical(存储历史数据)和MiddleManager(处理实时数据摄入)。
- Query 节点:Broker 节点接收查询请求,并将其路由到相应的Data节点。
- 元数据存储:使用外部数据库(如MySQL或PostgreSQL)存储元数据信息。
- 深度存储:依赖分布式文件系统(如HDFS或S3)进行数据备份和持久化。
这种模块化设计允许独立扩展各个组件,提高了系统的灵活性和可靠性。
数据结构
Druid 的数据模型基于以下概念:
- 数据源:类似于数据库中的表,每个数据源包含多个数据段。
- 数据段:数据的基本存储单元,按时间分区并包含列式数据。
- 列类型:支持多种类型,如时间戳、维度(用于分组和过滤)、度量(用于聚合计算,如求和、计数)。
- 索引:使用位图索引优化维度列的过滤操作,提升查询性能。
数据以时间戳为主键组织,便于时间范围查询和聚合。
简单入门Druid
要快速开始使用Druid,可以按照以下步骤:
- 安装:从Apache官网下载Druid发行版,或使用Docker镜像快速部署。
- 启动服务:运行单机模式(适用于测试)或分布式模式(适用于生产)。
- 摄入数据:使用内置控制台或API从文件(如CSV、JSON)或流式源(如Kafka)摄入数据。
- 查询数据:通过REST API或SQL接口执行查询,例如使用
SELECT * FROM datasource WHERE __time >= '2023-01-01'。 - 监控:利用Druid的控制台和日志监控系统状态和查询性能。
数据处理和存储支持服务
Druid 提供全面的数据处理和存储支持:
- 数据处理:支持数据转换、过滤和聚合在摄入阶段完成,减少查询时的计算负载。可通过Apache Kafka、Amazon Kinesis等集成实时流处理。
- 存储服务:数据持久化在深度存储(如云存储或HDFS)中,并自动复制以确保高可用性。Historical节点管理本地缓存以加速查询。
- 查询服务:通过Broker节点提供统一的查询接口,支持标准SQL和原生查询,并与工具如Grafana、Superset集成。
- 运维支持:包括自动数据段平衡、备份和恢复机制,以及监控指标导出到Prometheus等系统。
Druid 是一个强大的实时分析平台,结合了高性能、可扩展性和易用性,适用于大数据环境下的快速洞察和决策支持。
如若转载,请注明出处:http://www.wjstory.com/product/14.html
更新时间:2026-06-19 11:34:30