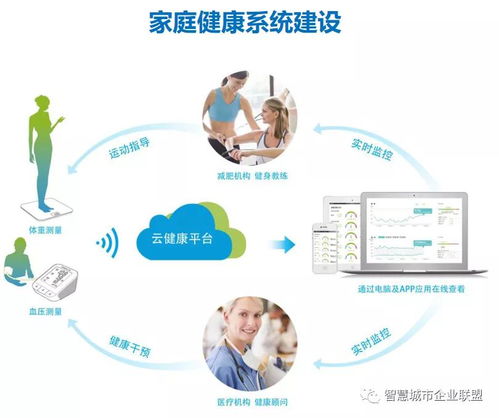
利用Redis高效存储特征数据 数据处理与存储支持服务实践
在构建现代线上服务,尤其是机器学习或推荐系统时,特征数据的高效存取是系统性能的核心。特征数据通常指用于模型预测或业务逻辑的各种属性值,如用户画像、商品标签、实时统计指标等。这些数据具有读取频繁、更新快、结构灵活且对延迟敏感的特点。传统的关系型数据库在此场景下往往力不从心,而Redis作为一种高性能的内存键值存储,凭借其丰富的数据结构、极致的速度和原子操作,成为存储线上服务特征的理想选择。
一、为什么选择Redis存储特征?
- 极致性能:Redis数据主要存储在内存中,读写操作通常在微秒级完成,能够满足高并发、低延迟的线上服务需求。
- 丰富的数据结构:除了简单的字符串,Redis支持哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)等。这允许我们以最自然的方式建模特征。例如,用户的所有特征可以存储为一个哈希,键为用户ID,字段和值对应特征名和特征值;排行榜类特征可以使用有序集合。
- 原子性与持久化:Redis的操作是原子性的,保证了并发下的数据一致性。它提供RDB快照和AOF日志两种持久化机制,可根据业务在性能与数据安全间做出权衡。
- 发布订阅与过期键:支持特征更新时的实时通知,以及为特征设置TTL,实现自动过期清理,非常适合缓存临时或会话级特征。
二、特征数据处理与存储架构设计
一个完整的特征存储支持服务通常包含以下层次:
- 数据生产层:负责特征的生成与计算。这包括离线批量处理(如Spark、Hive作业生成用户历史行为统计特征)和在线实时处理(如Flink流计算实时点击率)。处理后的特征被推送到消息队列(如Kafka)。
- 存储服务层(核心):消费消息队列中的数据,并写入Redis。这一层是关键,需要设计良好的键名规范和数据结构。
- 键名设计:遵循清晰的命名空间,例如
feature:user:{user<em>id}表示用户特征,feature:item:{item</em>id}表示商品特征。这便于管理和查找。
- 数据结构选择:
- 哈希:存储一个实体的多个字段,如
HSET feature:user:1001 age 25 city "北京" last_login 1672531200。适合字段多且需要单独更新的场景。
- 字符串:存储序列化后的复杂对象(如JSON或Protobuf)。适合一次性读取整个特征集合,但更新时需要整体覆盖。
- 有序集合:存储带权重的特征,如用户兴趣标签及其热度分数。
- 线上服务层:业务应用(如推荐引擎、风控模型)通过客户端直接访问Redis,获取所需的特征数据,进行实时预测或决策。
三、关键实践与优化策略
- 序列化与压缩:对于复杂的特征对象,选择高效的序列化协议(如MessagePack、Protobuf)并配合压缩(如Snappy),可以减少内存占用和网络传输开销。
- 批量操作与管道:使用Redis的
MSET、HMGET或管道(Pipeline)技术批量读写特征,可以大幅减少网络往返次数,提升吞吐量。 - 过期策略与内存管理:为不同类型特征设置合理的TTL。定期监控内存使用,对于不常访问的冷特征,可以考虑将其归档至成本更低的存储(如SSD-backed Redis或数据库),在需要时再热加载回Redis。
- 高可用与集群:生产环境必须使用Redis哨兵(Sentinel)模式或集群(Cluster)模式,避免单点故障。集群模式还能实现数据分片,突破单机内存限制。
- 监控与治理:建立完善的监控,关注QPS、延迟、内存使用率、命中率等核心指标。建立特征注册和血缘追踪机制,清晰掌握每个特征的来源、用途和存储位置。
四、示例:用户实时特征更新与查询
假设我们需要维护用户的“实时点击次数”和“最后点击商品”两个特征。
更新流程(数据处理服务):
1. 用户发生点击事件,日志发送至Kafka。
2. Flink流作业消费该事件,进行计数和最新商品ID的更新计算。
3. 计算后,Flink作业通过Redis客户端执行命令:
`bash
# 使用哈希,原子性地增加计数并更新最后商品
HSET feature:user:123 clickcount <新值> lastitem_id 456
# 同时为该键设置1小时过期,防止长期不活跃用户数据堆积
EXPIRE feature:user:123 3600
`
查询流程(线上推荐服务):
1. 要为用户123生成推荐,服务需要获取其特征。
2. 通过Redis客户端执行:HGETALL feature:user:123。
3. 将获取到的特征字典输入推荐模型,得到推荐结果。
五、
利用Redis存储特征,构建高效的数据处理与存储支持服务,是提升线上服务响应能力和用户体验的关键基础设施。成功的实践离不开合理的数据结构选型、清晰的键名规划、针对性能的优化以及对高可用和可观测性的重视。随着业务增长,特征数据的管理会愈加复杂,未来可考虑引入特征平台进行统一的生命周期管理,使特征成为企业更易用、更可靠的数据资产。
如若转载,请注明出处:http://www.wjstory.com/product/46.html
更新时间:2026-06-19 00:36:12