架构设计技术之分布式数据存储 数据处理与存储支持服务解析
在当今数据爆炸的时代,传统的集中式数据存储方式已难以满足海量数据处理、高并发访问和系统高可用性的需求。分布式数据存储作为现代架构设计的核心技术,通过将数据分散存储在多台独立的服务器上,并结合高效的数据处理与存储支持服务,为构建可扩展、高可靠、高性能的应用系统提供了坚实基础。
一、分布式数据存储的核心价值与挑战
分布式数据存储的核心价值在于其可扩展性、高可用性和容错性。通过水平扩展,系统可以近乎线性地提升存储容量和处理能力;通过数据多副本机制,保障了在部分节点失效时服务的连续性。这也带来了数据一致性、分区容错性、跨节点事务管理以及系统复杂度显著增加等挑战,这正是CAP定理、BASE理论等分布式理论需要解决的核心问题。
二、关键数据处理模式与架构
数据处理是分布式存储系统的灵魂,主要分为批处理与流处理两大范式。
- 批处理:针对静态的大规模数据集进行操作,如Hadoop MapReduce、Spark等框架,适用于历史数据分析、报表生成等场景。其架构通常遵循“分而治之”思想,将任务拆分到多个节点并行计算后汇总。
- 流处理:对连续不断产生的数据流进行实时或近实时处理,如Flink、Storm、Kafka Streams。其架构强调低延迟和状态管理,能够实现实时监控、即时推荐等业务需求。
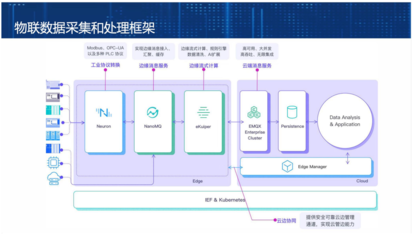
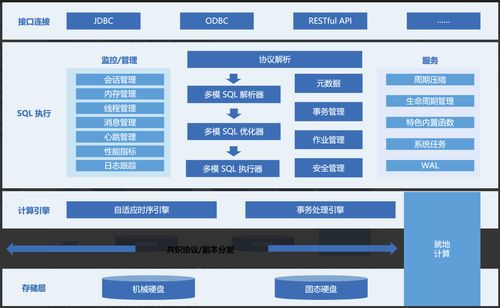
三、存储支持服务:数据管理的基石
分布式存储不仅仅是数据的存放地,更依赖一系列支持服务来实现高效、可靠的数据管理。
- 元数据管理:负责记录数据块的分布位置、副本信息、访问权限等,是系统寻址和调度的中枢。例如,HDFS的NameNode、Ceph的Monitor集群。
- 一致性协议与协调服务:确保在分布式环境下各节点状态协同一致。Paxos、Raft等共识算法是构建强一致性存储(如etcd、ZooKeeper)的核心,后者常作为分布式系统的配置中心、命名服务和分布式锁的实现基础。
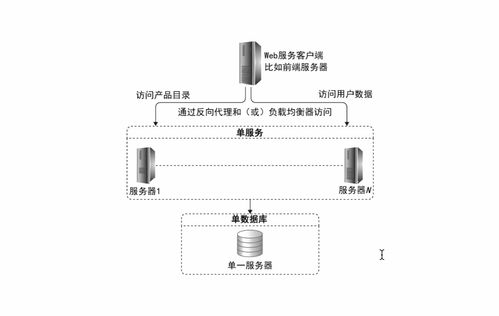
- 数据分区与路由:通过一致性哈希、范围分区等策略,将数据均匀分布到集群节点,并确保客户端能精准定位数据所在。这是实现负载均衡和横向扩展的关键。
- 副本管理与故障恢复:自动管理数据的多副本复制、放置策略(如机架感知),并在节点故障时触发副本重新复制与数据重平衡,保障数据的持久性与可用性。
- 分布式事务与锁服务:对于需要跨节点、跨分片保证ACID特性的场景,如分布式数据库,需要2PC、3PC、TCC等方案或全局时钟(如Spanner的TrueTime)来支持。
四、典型技术栈与选型考量
实践中,技术选型需紧密结合业务场景:
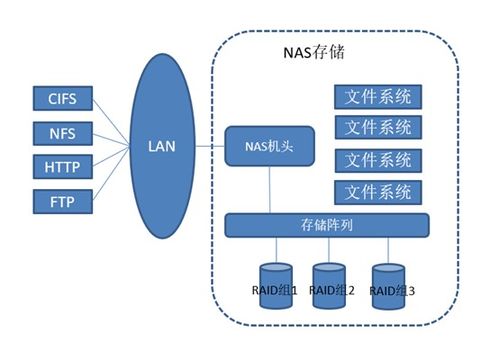
- 对象/块/文件存储:如Ceph、MinIO提供兼容S3的对象存储;HDFS适合大数据批处理场景。
- 分布式数据库:Cassandra、HBase适合海量KV存储;TiDB、CockroachDB提供NewSQL的分布式关系型能力;MongoDB提供文档模型的分布式支持。
- 缓存与内存网格:如Redis Cluster、Ignite,提供高性能的分布式缓存与内存计算。
选型时需权衡数据模型、一致性要求、读写模式、延迟敏感性及运维成本。
五、未来趋势与展望
随着云原生和算力网络的发展,分布式数据存储正呈现以下趋势:存储与计算进一步分离,以实现更极致的弹性;智能化的数据放置与流动策略,以优化性能和成本;Serverless数据库与存算一体架构的探索,旨在简化开发运维;以及对异构数据(图、时序、向量)的统一存储与处理支持,赋能AI与物联网应用。
分布式数据存储及其配套的数据处理与存储支持服务,构成了现代大规模应用的数据基石。深入理解其核心原理、技术组件与权衡艺术,是每一位架构师设计出健壮、高效、适应未来发展的系统所必备的技能。成功的架构永远是业务需求、技术可行性与运维复杂度之间的精巧平衡。
如若转载,请注明出处:http://www.wjstory.com/product/56.html
更新时间:2026-06-19 07:03:37